Where's the Chicken? Unpacking Spatial Awareness in Vision-Language Models
Introduction: The “What” vs. the “Where”
To truly understand an image, we have to treat it as more than a collection of pixels. As an image is a 2D projection of a fundamentally 3D world, mentally reconstructing the scene requires at least two components: recognizing “what” is in the image and understanding “where” those things are located.
This notion of “where” comes in two forms. One is the absolute where: identifying an object’s position on the image plane, often by drawing a bounding box around it. The other is the relational where: reasoning about how objects are situated relative to one another (e.g., “the chick is behind the cup” or “the car is to the left of the tree”). Both forms are important, but in this post we focus on the latter: how models reason about spatial relationships.
Coming back to the problem of image understanding, we cannot reliably infer the scene behind an image without knowing both what is present and where things are in relation to each other. Let’s consider a simple scene with two chicks sitting near a cup.

If someone asks, “Grab me the chick behind the cup,” the instruction only makes sense if we can correctly identify the “cup” (what) and accurately interpret what “behind” means in the appropriate reference frame (relational where). For example, if “behind” is defined relative to the camera’s viewpoint, it refers to the object that is farther away from the camera than the cup. This kind of relational reasoning is fundamental to real-world systems such as autonomous vehicles and robotic arms, where understanding both the objects and their spatial relationships is critical for safe and reliable action.
Modern vision-language models (VLMs), such as Gemini and ChatGPT, have become remarkably good at the what. When asked to describe an image or generate a caption, they often produce accurate and detailed responses. As these models grow larger and get trained on increasingly more datasets, their ability to recognize objects and describe their visible content continues to improve. In many evaluations[1][2], they already achieve near human-level performance at identifying what is present in an image.
However, when it comes to reasoning about where things are relative to each other, these same models often fall short.
This “what” vs. “where” paradox in modern VLMs becomes especially clear in combined reasoning tasks like “Find the hidden object.”View the actual conversation here.
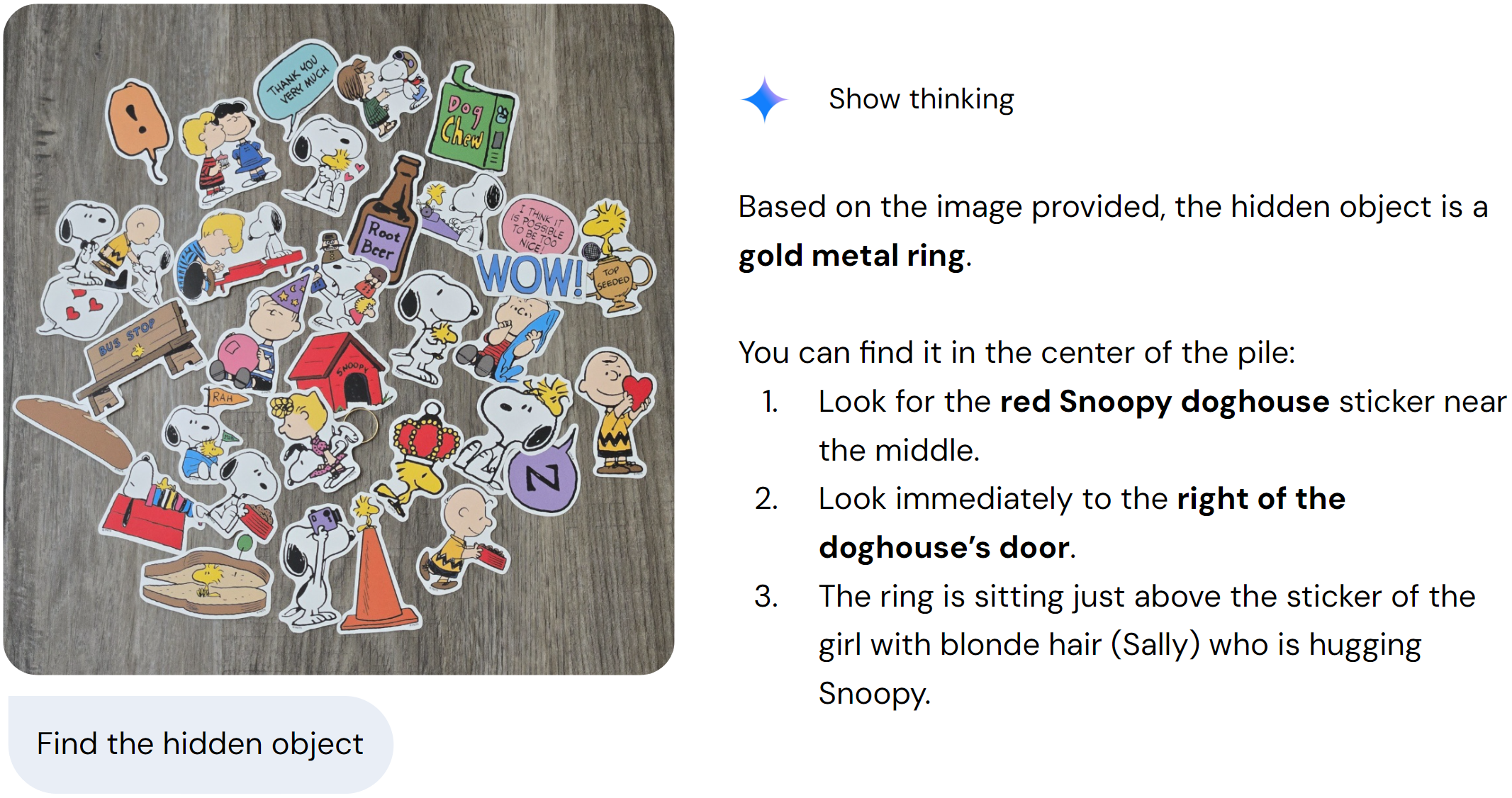
Larger version of the input image

In this example, the model (Gemini 3 Pro) correctly identifies the hidden object (the golden ring) but mislocates it. It claims that the ring is to the right of the red Snoopy doghouse, when in fact it is located below it. These mistakes may seem minor, but they expose a deeper and persistent limitation of modern VLMs: strong semantic recognition does not guarantee accurate relational spatial understanding.
We might expect this gap to shrink as models grow larger and are trained on more data. Yet, despite massive datasets and billions of parameters in state-of-the-art systems, this spatial weakness remains. A growing body of research suggests that the issue lies in the core architecture and training objectives of VLMs. In other words, the limitation stems not only from how much data we provide, but also from how these models are built and what they are fundamentally optimized to prioritize.
In this post, we take a closer look at the architectural roots of this spatial blindness in modern VLMs. We examine the building blocks that process visual information, the training objectives that favor certain capabilities over others, and why many recent fixes still fall short of fully solving the problem. Understanding why models struggle with this relational “where” and how we might overcome this limitation is a key step toward building vision systems that truly understand the worlds they see.
Why Does the VLM Architecture Forget Position?
To understand why VLMs often fail to capture spatial relationships, we need to look at their architectural foundation: the Transformer. Since its introduction in Attention is All You Need[3], the Transformer has become the backbone of modern language and vision-language models due to the power of its core building block, self-attention. In brief, self-attention measures how relevant one token (or word) is to another. For example, in the sentence, “Here is a yellow chick,” the method learns that “yellow” is closely tied to “chick” because it describes it.
However, pure self-attention has a critical blind spot: it does not care about order. If we only rely on relevance between tokens, the sentences “The chick is in front of the cup” and “The cup is in front of the chick” look identical, even though they describe entirely different spatial situations. Without any notion of token position, the model collapses the sentence into something like a bag-of-words representation, where only co-occurrence matters, not who is in front of whom.
When we move from text to images, the problem intensifies. A typical VLM first chops an image into a grid of patches (for example, 16x16 or 32x32), converts the patches into tokens, and then feeds the resulting sequence into the Transformer. Without positional information, the model treats the image as a bag-of-patches. It may recognize that there is a chick and a cup, but it has no built-in mechanism to tell whether the chick patch is to the left, above, or behind the cup patch.
The Evolution of Positional Encodings
To fix this, researchers developed a series of positional encodings that tag tokens or patches with location information. Many of these methods were originally developed to handle word order in sentences, but here we focus on what happens when they are applied to images.
Rough graphical representation of positional encodings on 2D images
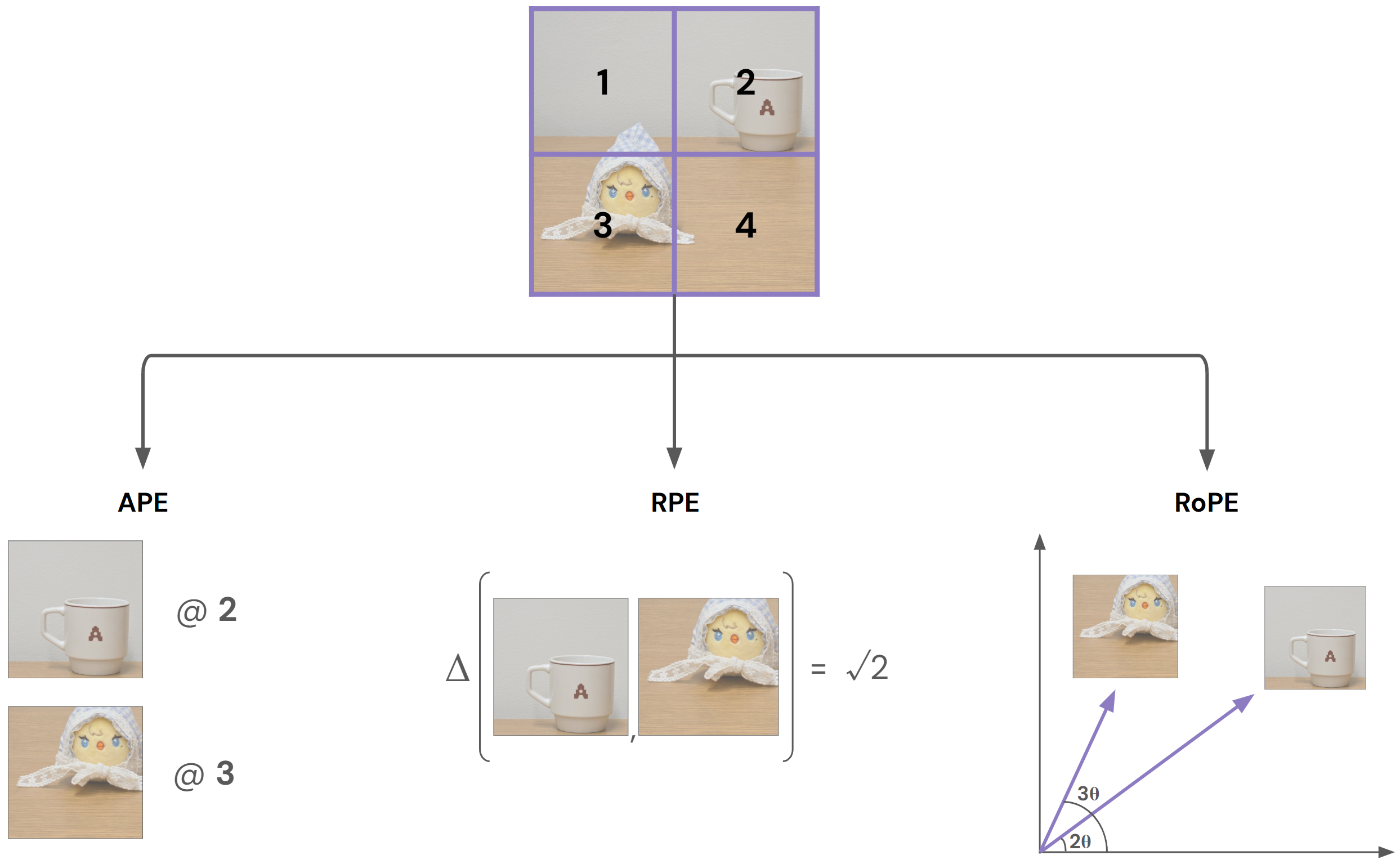
Top: The scene is split into four patches, labeled 1-4.
Bottom left (APE): Each patch is tagged with an absolute index (cup is at 2, chick at 3).
Bottom middle (RPE): Relative distances between each patch are encoded.
Bottom right (RoPE): Patch positions correspond to rotations in embedding space, with angles increasing by index.
Note: This schematic is intended solely to illustrate key differences between APE, RPE, and RoPE for conceptual understanding. It does not capture the actual computations or values used in real models.
The original Transformer paper introduces absolute position encoding (APE), which assigns a unique fixed vector to every patch. This works if all input images share the same size, but fails when the resolution changes. If a model is trained on 224x224 images, it learns positional vectors tied to that grid. At test time, if given a larger image, the model cannot naturally represent the extra patches. A common workaround is to stretch or interpolate embeddings to a new size, but this distorts spatial relationships. The model overfits to specific locations, limiting its ability to generalize or be translation-invariant.
To move beyond fixed grid sizes, later work introduces relative position encoding (RPE)[4]. Instead of defining where a patch is globally, RPE says where it is relative to other patches (for example, “The chick patch is two steps away from the cup patch”). Self-attention already works on pairwise relationships, so this approach feels like a natural fit, and the model can handle variable-length inputs and different layouts more gracefully. But for 2D images, there is a trade-off. RPE largely discards absolute coordinates, which are crucial for localization-heavy tasks like object detection. If you care about exactly where a pixel or patch is in the image, a purely relative scheme can degrade performance on tasks that demand precise spatial grounding[5]. Also, many RPE implementations do not work well with key–value (KV) caching. Relative distances depend on the current sequence length, so the model must recompute attention scores when the length changes. This leads to higher memory and computation costs for long contexts.
Today, the de facto standard for large language models and many VLMs is rotary positional encoding (RoPE)[6]. RoPE aims to get the best of both APE and RPE: it preserves absolute position information while using rotation operations to naturally represent relative distances. This design often generalizes better to longer sequences and has proven robust in text generation. But this method is built for 1D token sequences. When applied to images, it requires flattening the 2D grid into a 1D line, breaking spatial locality: patches that are neighbors vertically might end up far apart in the flattened sequence. To address this, models like Qwen2-VL[7] introduce a multimodal variant (M-RoPE) that splits the rotary embedding into temporal, height, and width components, and applies separate rotations to each. Still, these encodings are fundamentally 2D and do not capture depth or full 3D spatial relationships without extra geometric signals.
The “Semantic Loudness”
Let’s imagine there exists a positional encoding scheme that perfectly preserves 3D structure. Even with such an ideal encoding, a growing line of work suggests spatial reasoning would still remain a persistent weakness. The problem is not only how good our positional encodings are, but also how the Transformer processes them internally. Recent work points to a deeper issue inside the Transformer itself: a phenomenon often referred to as embedding norm suppression[8]. Transformers excel at building high-dimensional vectors that encode what is in each patch, such as ‘a yellow chick’ or ‘a ceramic cup.’ These semantic embeddings have large vector magnitudes; in other words, they are loud in the embedding space. Positional encodings, in contrast, are quiet and contribute only a small magnitude to the final representation. During self-attention, the semantic content dominates computation and drowns out the quieter positional signals. As a result, the model often behaves as if position barely matters, even with careful encoding.
This effect becomes evident in a simple permutation test. Take an image, break it into patches as usual, but then randomly shuffle the order of the visual tokens so that the original spatial layout is destroyed. Many VLMs show only a negligible drop in performance on standard benchmarks. For example, consider the following captioning example:
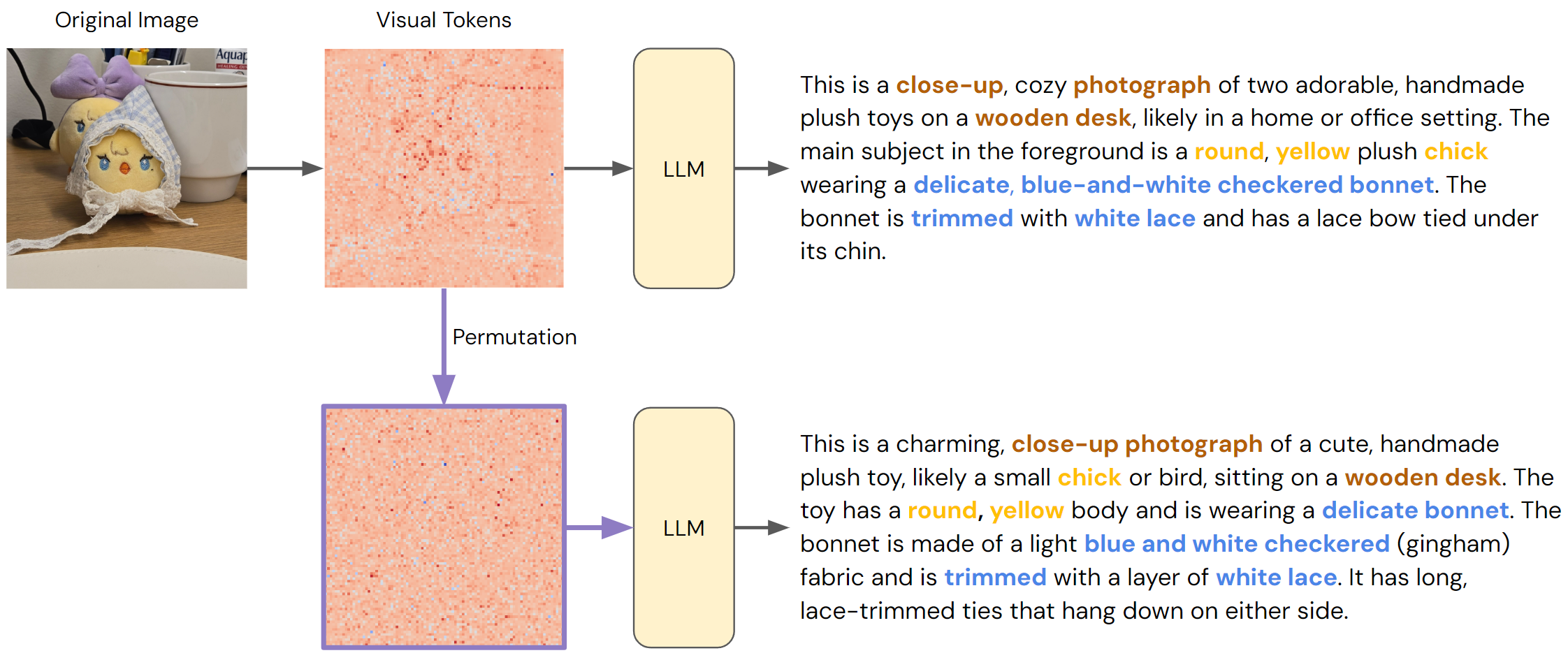
Even after random shuffling, the generated captions remain nearly identical because the model still identifies the objects (“chick” and “blue bonnet”) and produces a reasonable description of the scene. This indicates that positional encodings, including mechanisms like M-RoPE, have little effect on the model’s output. Instead, the model appears to treat the image as a bag of semantic features.
To counteract this, recent work proposes embedding norm normalization[8]. The idea is simple: rescale the magnitudes of the visual feature embeddings. This makes the semantic content and positional signals comparable in scale. As a result, the model pays more attention to positional cues, improving spatial reasoning without sacrificing overall semantic understanding.
However, balancing signal magnitudes is only a partial fix. It shows that positional information is “quiet” relative to semantics, but even after that correction, deeper issues remain. Spatial reasoning goes beyond simply knowing coordinates. Encodings like APE, RPE, and RoPE can indicate where the patches are and how far apart they are, but they do not capture the structure of the scene. Many spatial questions depend on richer relations, such as containment (“Is the water in the cup?”), occlusion (“Is the chick behind the cup?”), and relative depth. These concepts require structured spatial reasoning and domain-specific visual priors, not just louder positional coordinates. In other words, making position information “loud enough to hear” is necessary, but not sufficient for VLMs to reason about space as humans do.
Attention Allocation Problem: Do VLMs Look at the Right Place?
Beyond how models encode position, another line of work asks a different question: where do models actually focus their attention? These studies suggest that many spatial errors arise not because positional information is missing, but because the model looks at the wrong place. In VLMs, this happens at two levels: between modalities (text vs. image) and within the image itself (relevant vs. irrelevant regions).
Text Dominates, Vision Follows
VLMs typically process two inputs: the image (e.g., a chick and a cup on a table) and the text (e.g., “Describe the image” or “Where is the chick relative to the cup?”). Architecturally, the visual backbone converts image patches into patch embeddings, and the language backbone (usually a powerful LLM) encodes the text. These two pieces are then fused so the model can jointly reason over both modalities.
However, prior work[9][10] repeatedly finds these inputs do not contribute equally. LLM backbones are much more heavily trained and semantically richer than visual encoders. As a result, the combined model develops a strong textual bias. This mirrors the semantic loudness effect we saw earlier, where rich language semantics drown out the weaker visual evidence. One study[11] quantifies this imbalance: roughly 90% of the attention flows to textual tokens, with only about 10% going to the visual tokens. The model leans heavily on the prompt and its internal language statistics, and only lightly consults the image.
This imbalance also contributes to the failures we see in spatial reasoning. The model hallucinates what should be there instead of faithfully reporting what is there. If it knows that clouds are usually above the grass, it may claim that relation even if the image is upside down with the clouds below. The model often sees what it expects from language, not what the pixels actually show. In this view, many spatial errors stem less from model limits but more from uneven attention between modalities. VLMs tend to trust text more than vision.
A natural reaction is to simply increase attention to visual tokens. But that alone is not enough. Even if the model looks more at the image, if it focuses on the wrong regions, spatial reasoning will continue to fail.
Misdirected Gaze
Even if we manage to encourage a VLM to rely more on visual input, a second failure mode appears: the model may simply look in the wrong place.
Consider asking, “Where is the chick in relation to the cup?” Ideally, the model should focus on patches containing the chick and cup. However, empirical analyses[11] show that VLMs often scatter attention across irrelevant regions, such as the table or wall, and pay little attention to the objects in question. The model may be “looking at the image,” but not at the evidence needed to answer the question.
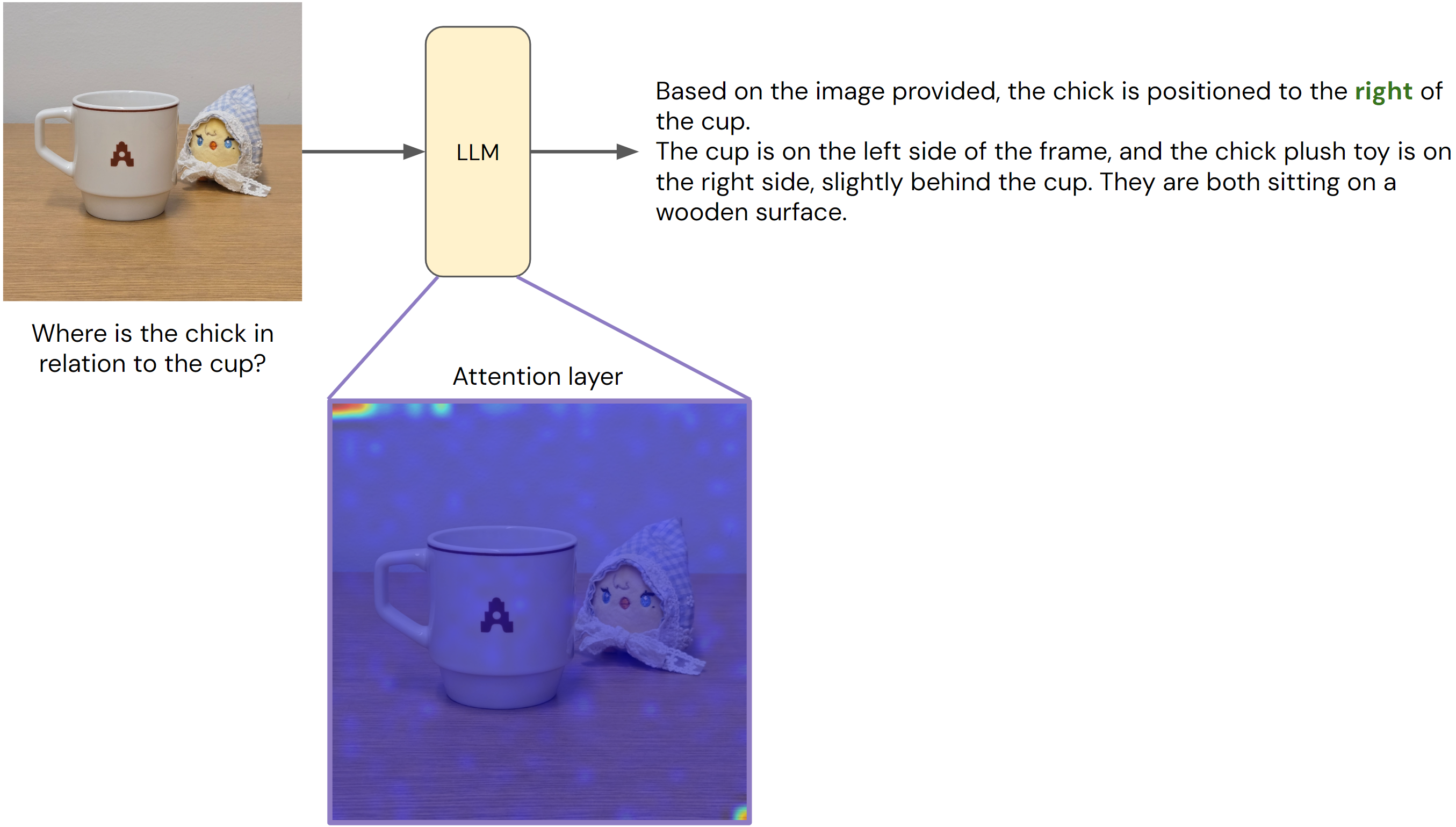
To address this, a recent work proposes AdaptVis[11], a training-free method that redirects attention at inference time. The key idea is to dynamically adapt the model’s visual attention pattern using its own prediction confidence. When the model is confident, AdaptVis sharpens the attention distribution, narrowing the focus to regions the model already considers relevant. When the model is uncertain, AdaptVis broadens the attention window, encouraging exploration of a wider area and potentially discovering objects and relationships it initially overlooked. This confidence-guided adjustment shows strong empirical gains, including gains of up to 50% on certain subset of the WhatsUp dataset[12]. More broadly, it suggests that many spatial failures arise not from the lack of capability to reason about space, but from failing to focus on the right evidence at the right time.
Effect of applying AdaptVis to the chick and cup image


AdaptVis and similar methods show that attention allocation is crucial for spatial reasoning. They show that VLMs often underuse available visual information and that steering attention can significantly improve performance.
However, AdaptVis is not a complete solution. As the method operates purely at inference time, it cannot change the model’s internal representation or how the spatial relations are learned in the first place. If the model never learned concepts like “in front of” vs. “behind,” simply pointing its attention more precisely will not fully close those gaps. In other words, attention steering helps the model make better use of what it already knows, but by itself, it cannot guarantee the richer, human-like spatial reasoning that many applications require.
From Global Glance to Localized Training: What are VLMs Designed For?
The methods introduced so far (embedding norm normalization and AdaptVis) can be viewed as post-hoc fixes. They operate on top of an already trained architecture, leaving both the original model design and its pretraining objectives unchanged. While these approaches do improve performance, a growing body of work argues that true spatial awareness cannot simply be patched in with auxiliary mechanisms. Instead, the problem lies in how these models are trained from the beginning.
The dominant paradigm for large-scale VLM training is Contrastive Language-Image Pretraining (CLIP)[13]. In this framework, a model is trained on large collections of image–caption pairs (e.g., COCO) to match each image with its corresponding text description. Fundamentally, this is global: the model aligns the entire image with the entire caption. As a result, it is strongly encouraged to encode the overall meaning and semantic themes of a scene. This is what gives modern VLMs their impressive ability to fluently and accurately describe images. But it also builds in a limitation: the training objective rewards learning what is in the image, while largely ignoring where those entities are located. Spatial structure is, at most, learned only indirectly.
To address this limitation at its source, recent work proposes Contrastive Localized Language-Image Pretraining (CLOC)[14], a framework that explicitly incorporates spatial grounding into the pretraining objective. Under CLOC, the model is no longer trained solely to align the whole image with the whole caption. Instead, it is encouraged to learn both object identity and object location, producing representations that are grounded at a finer, region-aware level. This allows the visual backbone to encode spatial information directly into its features, rather than relying on later-stage corrections. The added localization signal does not come at the cost of standard image-level performance. CLOC slightly improves image-level retrieval and classification by 0.8% when compared with CLIP, while also achieving roughly 57% accuracy on region-level retrieval and classification.
But this kind of localized pretraining comes with a substantial cost. To use it, we will need to retrain the visual backbone from scratch, which is computationally expensive and time-consuming (especially for state-of-the-art VLMs that already represent years of training effort). This motivates a parallel line of research focusing on modular interventions: methods that aim to inject spatial awareness into existing, frozen models without full retraining. One example is Positional Insert (PIN)[15], an input-agnostic, learnable spatial prompt with a small number of parameters that can be inserted into a frozen VLM to unlock object localization capabilities. Another is Twist & Scout[16], which modifies the language model’s decoder with a dual mixture-of-experts design: one expert remains frozen to preserve the original CLIP-style semantics, while a second expert is specialized for location grounding. At inference time, the model dynamically switches between these experts depending on the task.
These methods represent an important first step toward models that are natively capable of object localization, but they also highlight several remaining fundamental challenges. For unified models like CLOC, beyond the cost of retraining, a central question is how much spatial information can be injected without affecting global semantic understanding. It remains unclear how to balance learning what and learning where within a single system: how much representational capacity and attention should be devoted to semantics vs. spatial structure, and how that balance should adapt across different levels of visual complexity. In modular designs, maintaining strong semantic experts while adding dedicated spatial experts increases computational and memory overhead. Because these approaches rely on frozen backbones, they also limit how deeply spatial information can be integrated into the visual feature hierarchy; spatial cues are often introduced only at later stages (for example, at the decoder), constraining the model’s ability to form truly grounded representations.
Taken together, these challenges suggest that localized and modular interventions are promising but unlikely to solve spatial reasoning on their own. Overcoming the “what” vs. “where” divide will likely require coordinated advances in model architecture, training objectives, supervision signals, and other parts of the learning pipeline, rather than isolated fixes applied at a single point.
Conclusion: Path Towards Spatially-Aware VLMs
Stepping back, a consistent picture emerges: today’s VLMs are very good at answering “What’s in the image?” but far less reliable at answering “Where is it relative to that?” This weakness does not disappear with more data or larger models. Instead, it makes us trace back to how these systems are built and trained. Transformers are naturally position-agnostic, positional encodings get drowned out by rich semantic features, and training pipelines reward capturing the overall gist over spatial precision.
Throughout this post, we have seen several promising attempts to narrow this gap: more expressive positional encodings (from APE to RPE to RoPE and M-RoPE) to better preserve the 2D layout of images, embedding norm normalization to help positional signals compete with loud semantic embeddings, attention-steering methods to guide models to look at the right regions, and training strategies to push models to encode not only what objects are present, but also where they are in the scene.
Still, none of these approaches fully solves spatial reasoning on its own. Spatial awareness does not emerge from plugging in a single clever module; it arises from the interaction among the architecture, attention, and training objectives. Moving toward spatially-aware VLMs will likely require these strands to work together, along with a deeper understanding of each component: positional schemes that respect 2D (and ultimately 3D) structure, mechanisms that reliably guide attention to the right evidence, and objectives that genuinely demand spatial precision. To develop agents that can act safely and effectively in the physical world, we must treat where not as a byproduct of what, but as a first-class goal of visual intelligence.
Show References (16)
- Lin, T. Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Doll'ar, P., & Zitnick, C. L. (2014). Microsoft coco: Common objects in context. In European conference on computer vision. (pp. 740--755).
- Antol, S., Agrawal, A., Lu, J., Mitchell, M., Batra, D., Zitnick, C. L., & Parikh, D. (2015). Vqa: Visual question answering. In Proceedings of the IEEE international conference on computer vision. (pp. 2425--2433).
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, \., & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30.
- Shaw, P., Uszkoreit, J., & Vaswani, A. (2018). Self-attention with relative position representations. arXiv preprint arXiv:1803.02155.
- Wu, K., Peng, H., Chen, M., Fu, J., & Chao, H. (2021). Rethinking and improving relative position encoding for vision transformer. In Proceedings of the IEEE/CVF international conference on computer vision. (pp. 10033--10041).
- Su, J., Ahmed, M., Lu, Y., Pan, S., Bo, W., & Liu, Y. (2024). Roformer: Enhanced transformer with rotary position embedding. Neurocomputing, 568, 127063.
- Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., & et al. (2024). Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution. arXiv preprint arXiv:2409.12191.
- Qi, J., Liu, J., Tang, H., & Zhu, Z. (2025). Beyond Semantics: Rediscovering Spatial Awareness in Vision-Language Models. arXiv preprint 2503.17349. https://arxiv.org/abs/2503.17349
- Zhou, Y., Cui, C., Yoon, J., Zhang, L., Deng, Z., Finn, C., Bansal, M., & Yao, H. (2024). Analyzing and Mitigating Object Hallucination in Large Vision-Language Models. In The Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=oZDJKTlOUe
- Sun, Z., Shen, S., Cao, S., Liu, H., Li, C., Shen, Y., Gan, C., Gui, L., Wang, Y. X., Yang, Y., & et al. (2024). Aligning large multimodal models with factually augmented rlhf. In Findings of the Association for Computational Linguistics: ACL 2024. (pp. 13088--13110).
- Chen, S., Zhu, T., Zhou, R., Zhang, J., Gao, S., Niebles, J. C., Geva, M., He, J., Wu, J., & Li, M. (2025). Why Is Spatial Reasoning Hard for VLMs? An Attention Mechanism Perspective on Focus Areas. In Forty-second International Conference on Machine Learning. https://openreview.net/forum?id=k7vcuqLK4X
- Kamath, A., Hessel, J., & Chang, K. W. (2023). What's ``up'' with vision-language models? Investigating their struggle with spatial reasoning. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. (pp. 9161--9175). Association for Computational Linguistics. https://doi.org/10.18653/v1/2023.emnlp-main.568
- Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., & et al. (2021). Learning transferable visual models from natural language supervision. In International conference on machine learning. (pp. 8748--8763).
- Chen, H. Y., Lai, Z., Zhang, H., Wang, X., Eichner, M., You, K., Cao, M., Zhang, B., Yang, Y., & Gan, Z. (2025). Contrastive Localized Language-Image Pre-Training. In Forty-second International Conference on Machine Learning. https://openreview.net/forum?id=sGQEOXlezg
- Dorkenwald, M., Barazani, N., Snoek, C. G., & Asano, Y. M. (2024). Pin: Positional insert unlocks object localisation abilities in vlms. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. (pp. 13548--13558).
- Bhowmik, A., Derakhshani, M. M., Koelma, D., Asano, Y. M., Oswald, M. R., & Snoek, C. G. (2025). Twist & scout: Grounding multimodal llm-experts by forget-free tuning. In Proceedings of the IEEE/CVF International Conference on Computer Vision. (pp. 1359--1368).
BibTeX
@inproceedings{pyo2026wheres,
title={Where's the Chicken? Unpacking Spatial Awareness in Vision-Language Models},
author={Jiyoon Pyo and Yao-Yi Chiang},
booktitle={The Blogpost Track at ICLR 2026},
year={2026},
url={https://openreview.net/forum?id=XSZV6I3icC}
}